About spatial-analyst.net
|
 spatial-analyst.net logo is a non-commercial website intended for users interested in advanced use of geocomputational tools. The topics discussed generally belong to spatio-temporal data analysis sciences, digital cartography, geomorphometry, geostatistics, geovisualization, GPS tracking and navigation, raster-based GIS modelling and similar. Most of the articles presented are only supplementary materials to various research publications. Visitors of the website are kindly asked to refer to the peer-reviewed publications, when citing some of the materials, instead of referring to the URL of an article. All materials are prepared on an informative basis only. This is a wiki project, which obviously means that you can edit, extend and modify much of its content. Please also read the disclaimer before using some of the materials. and NO! This site has not much to do with the ESRI's spatial analyst extension.
|
How to / Where to...
|
|
|
|
|
|
|
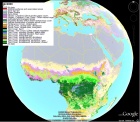 WorldGrids.org: publicly available environmental layers WorldGrids.org is a repository of environmental layers at 1km resolution of interest for soil, meteorological and climatological mapping, for species distribution modeling and various spatial analyses. Via WorldGrids.org you can also find a systematic review of the public data sources grouped by a theme. WorldGrids.org is one of the components of GSIF (Global Soil Information Facilities) which forms a major component of ISRIC's mandate to serve the international community by preserving soil data and delivering value-added products with global coverage in an open access format.
|
|
|
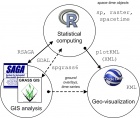 Typical software combo used at GEOSTAT Summer Schools The GEOSTAT Summer School for PhD students and R-sig-geo enthusiasts. The main idea of GEOSTAT is to promote various aspects of statistical analysis of spatial and spatio-temporal data using open source / free GIS tools: R, SAGA GIS, GRASS GIS, FWTools, Google Earth and similar. It is sort of a mini-conference (a list of tutorials) focused on new functionality and new developments considering the software tools for spatio-temporal statistics. Members of the scientific committee are typically the main developers and maintainers of the R + OS GIS tools (that have kindly accepted to teach on the summer shool without any honorarium payment).
|
|





